

The most basic definition of a database is a collection of similarly structured data related to a specific topic. Databases represent an automated version of a manual filing and retrieval system. Good database design requires a carefully defined structure be set up first to store the data.
We will first look at a list of employees to help explain some basic terminology common to all databases.
Example 1: Exploring an Employee List
A list of employees is simply a table or collection of similarly structured data with rows and columns. Each row contains information about an individual employee, and each column contains a specific piece of information about an employee. If you wanted to track this data in Access, you would probably track such fields as employee id, first and last name, date hired, salary, etc. In the example below, you'll see some key terms and concepts that are common to all databases:
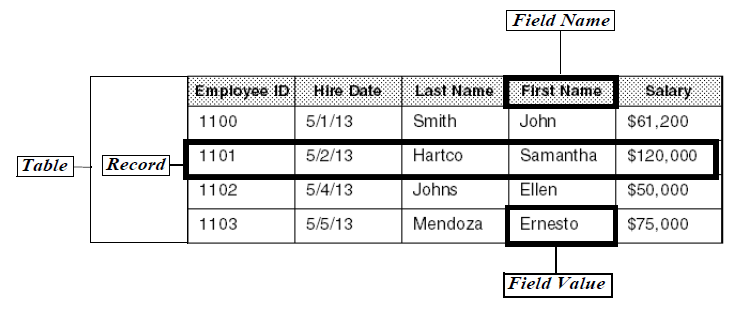
Table
A table is a complete set of information. Tables store the data in Access. A single complex database may contain hundreds or even thousands of individual tables. A single table may have only one row of information, or it may contain thousands or even millions of rows. The list of employees would be stored
Records
An individual entry in a table is called a record. A record is a row of data. In this example, a record consists of all the information stored about a particular employee, including employee ID, hire date, last name, first name, and salary. Thus, each employee has a unique record in the table, and this table includes a total of four records.
NOTE: Some database programs refer to records as rows.
Fields
Each row or line in a table contains specific pieces of information called fields. A field consists of one item of data. In this example, fields are referred to by the following field names or labels:
- Employee ID
- Hire Date
- Last Name
- First Name
- Salary
NOTE: Some database programs refer to fields as columns.
Database Objects
A database is a collection of tables and associated objects used to automate information management. There are four main objects in a database, which we will cover in this workshop:
- Tables hold or contain the data.
- Queries ask questions of the data and produce those results.
- Forms are used for data entry or data modification.
- Reports create printouts of the data.
A relational database may contain hundreds or even thousands of different objects to track information.
Primary Key
The primary key of a table is a field, or group of fields, that uniquely identifies each record. Another characteristic of a primary key field is that it cannot be left blank in a record. Primary keys also allow the database program to quickly search records in a table. With that in mind, it is a good idea to assign a primary key to every table in a database. Since the employee ID is unique for each employee, it's a naturally occurring primary key for this example. Note that the data in any table is displayed in primary key order by default.
Example 2: Exploring a Contact List
Our second example, a contact list with names, email addresses, and phone numbers, illustrates an important concept concerning the primary key.
| Last Name | First Name | Phone | |
|---|---|---|---|
| Abbot | Barbie | barbnfred@example.com | 812-332-3488 |
| Abbott | Thomas | tabbott@example.com | 812-332-3847 |
| Abbott | Thomas | tommy_a@example.com | 812-334-9877 |
| Abdon | Fred | barbnfred@example.com | 812-332-3488 |
A contact list does not have a naturally occurring primary key since none of the fields in the table are guaranteed to have a unique value for every record. For example, more than one person might be named John Smith and there might be more than one person living at a single address or even using the same email address. In cases such as this, Access can create an additional field for each record to act as the primary key. This field, called an AutoNumber field, will contain a number unique to each record. Access will automatically insert the new number when new records are added to the table.
One way to structure a contact list database is shown in the following table:
| ID | Last Name | First Name | Phone | |
|---|---|---|---|---|
| 1 | Abbot | Barbie | barbnfred@example.com | 812-332-3488 |
| 2 | Abbott | Thomas | tabbott@example.com | 812-332-3847 |
| 3 | Abbott | Thomas | tommy_a@example.com | 812-334-9877 |
| 4 | Abdon | Fred | barbnfred@example.com | 812-332-3488 |
Based on the AutoNumber field, Access has assigned a unique ID number to every individual.
Exploring Relational Database Concepts
A Relational Database is a collection of data built using a relational model. Relational databases have the ability to relate data in two or more tables – for example, a business might have a table containing demographic information about its customers (e.g., name, address, and phone number) and a separate table tracking the orders that each customer placed with the business. It would be essential to have the ability to relate the data in the two tables to see which order belonged to which customer. Applications that have the ability to relate data in one table to data in another table are called Relational Database Management Systems (RDBMS). Access is a Relational Database Management System.
By contrast, a flat file database limits a user to working with only one table that stores data. Examples might include a contact list or a budget. Because these examples would only need one table, they could be used effectively in a flat file database program. Flat file data can often be stored and managed in an Excel spreadsheet.
There are many situations in which the data is too complicated to be stored in one table. In those situations, a flat file database is not adequate. There are several advantages in distributing data among individual tables in relational databases, rather than storing all of the data in one large two-dimensional table. One advantage is not having to repeat data in multiple locations.
Tables are the fundamental objects at the heart of a relational database since they store the data. In a relational database program like Access, users can work with multiple tables simultaneously to obtain the results that they want since the tables can be related.
Comparing a Flat File and a Relational Database
In this course, we will play the role of a college wanting to build a database to track its faculty and their departments. We will first look at this as a single flat file data set in Excel, and then discuss how we would organize it as a relational database in Access.
Step1. To open the epclass folder, on the desktop,
Double-Click the epclass folder
Step2. To navigate to the correct folder,
Double-Click the Access-The Basics folder,
Step3. To open the Excel file,
Double-ClickFlatFileData.xlsx
Step4. To close Excel, in the upper-right corner,
Click![]()
Creating Multiple Tables
The solution is to break down the data into separate tables in a relational database program. The following diagram shows how we'll break the data into separate tables.
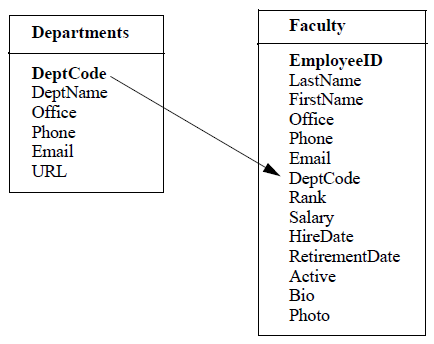
The Departments table contains only those fields relevant to a department and the Faculty table contains only those fields relevant to a faculty member. The tables are then related by their shared department code field. DeptCode is the primary key field in the Departments
This relationship represents reality, in that one department can have many faculty members working for it. Additionally, if a department name, location, or phone number changes, we would only need to update that information in a single record rather than in the multiple records that department would have in the flat file spreadsheet.
We'll discuss foreign keys and the one-to-many relationship in more detail later in the course.
Thinking about Database Design
Now that you are familiar with some basic database terminology, you can begin thinking about simple database design and how to organize data into individual tables. Before designing a database, you will want to take some time to follow these simple guidelines:
- Think about what reports you want to generate in order to better determine the data you need to track.
- After deciding what data to track, organize the data so that related fields are grouped logically into individual tables.
- Determine each table's primary key. If a table does not have an appropriate field that can be used as a primary key, consider using an AutoNumber field.
Following these guidelines will help avoid data redundancy so that data will not have to be entered multiple times in different tables.
In this course, we will start by opening a simple one-table database which contains a list of faculty. We will use this to better understand the kinds of information that can be stored in fields and how to enter and edit data. Later in the course, we will create a second table that contains a list of departments and learn how to create a one-to-many relationship between the tables so that we can easily and efficiently determine which faculty belong to each department.